ChatGPT „weiß“ gar nichts

LLMs lügen
„Wir bauen keine Applikationen, die Wissen aus Sprachmodellen ziehen.“ Das ist einer unserer wesentlichen Leitsätze. Diese Aussage wundert Kunden oft, aber wer sich mit Large Language Models auskennt, kommt unweigerlich zur gleichen Schlussfolgerung: Sprachmodelle sind bis zur Nutzlosigkeit unfähig, Wissen verlässlich zu reproduzieren, selbst wenn genau dieses Wissen in ihren Trainingsdaten enthalten war.
Trotzdem sind viele der unzähligen Prompts und Anwendungen, mit denen man täglich konfrontiert wird, ganz genau darauf ausgelegt: Ohne weiteren Input werden ChatGPT oder Gemini oder Claude verwendet, um „Fakten“ zu produzieren. Das ist aus meiner Sicht fahrlässig bis unseriös, selbst spezifisch nachtrainierte Sprachmodelle sind keine verlässlichen Experten.
Halluzinationen sind kein kleines Problem, das man als unwesentliche Nebenwirkung abtun kann. Halluzinationen werden auch nicht verschwinden, wenn „die Modelle immer besser werden“. Solange der technische Ansatz gleich bleibt, bleiben uns auch die Halluzinationen erhalten. Sie treten vermehrt dort auf, wo die Trainingslage dünn war, z.B. wenn man sich bei OpenAi aus dem englischen Sprachraum heraus bewegt und wenn es zu einem Thema im Trainingskorpus nur wenige Texte gab. Häufig im Trainingsset repräsentierte Fakten lassen sich verlässlich abfragen, seltener repräsentierte werden verzerrt. Im Falle von gar nicht repräsentierten Fakten werden alternative Aussagen frei erfunden.
Dieses Problem betrifft natürlich nicht nur GPT, sondern alle Large Language Models. Je kleiner das Modell, desto ausgeprägter ist der Effekt im Allgemeinen.
Eine Frage - viele falsche Antworten
Um das mal etwas greifbarer zu machen, haben wir mal wieder eine Faktenfrage durch mehrere Sprachmodelle geschickt. Fairerweise verwenden wir immer die gleiche Frage, nämlich: „Wer war Georg Lohmeier“.
Da den Herrn vielleicht nicht jeder kennt, hier als Referenz der erste Abschnitt seiner (deutschen) Wikipedia-Seite:
Georg Lohmeier, Pseudonym Tassilo Herzwurm (* 9. Juli 1926 in Loh; † 20. Januar 2015 in München) war ein deutscher Schriftsteller, Dramatiker, Regisseur und Schauspieler. Er ist Autor verschiedener Theaterstücke und Fernsehserien wie Königlich Bayerisches Amtsgericht oder Zwickelbach & Co. und mehrerer Stücke des Komödienstadels. Kurzzeitig war er Oberjuror bei der Sendung Dalli Dalli.
Ältere Semester erinnern sich an das „Königlich Bayerische Amtsgericht“, jüngere kennen nicht einmal mehr „Dalli Dalli“. Dennoch handelt es sich definitiv um eine Persönlichkeit des öffentlichen Lebens, es gibt mehr als genug Zeitungsartikel, Bücher und Bilder rund um seine Person.
Damit ist also anzunehmen, dass die wesentlichen Fakten über ihn auch in den Trainingssets der meisten Large Language Models vertreten sein dürften, wenn auch sicher nicht in großem Umfang.
Wenn wir annehmen, dass ein LLM als „Wissensspeicher“ taugt, dann muss sich dieses Wissen auch verlässlich abrufen lassen.
Schauen wir uns zuerst ChatGPT 3.5 an (das aktuell frei verfügbare und deswegen am häufigsten genutzte Modell).

Georg Lohmeier landet in der richtigen Kategorie, aber danach geht es steil bergab:
- Geburtsdatum falsch
- Geburtsort falsch
- Sterbedatum falsch
- Werke falsch
- Auszeichnungen falsch
Vielleicht muss man ja bezahlen, um an die Fakten zu kommen?
ChatGPT 4 gibt tatsächlich eine - etwas - besser Antwort:

Aber:
- Geburtsdatum falsch (wenn auch etwas näher an der Wahrheit)
- Geburtsort falsch
- Sterbedatum falsch
Wenigstens stimmt hier das Hauptwerk und auch die Tätigkeiten sind korrekt dargestellt. Aber warum es so schwer ist, die Datumsangaben vollständig korrekt hinzubekommen, bleibt ein Rätsel.
Wenden wir uns dem Newcomer zu: Mistral. Der Firmensitz in Paris suggeriert ja einen etwas europäischeren Fokus und deutschsprachige Dokumente (sicher auch Wikipedia) sind auch definitiv Teil der Trainingsdaten.
Das Ergebnis ist allerdings ernüchternd:
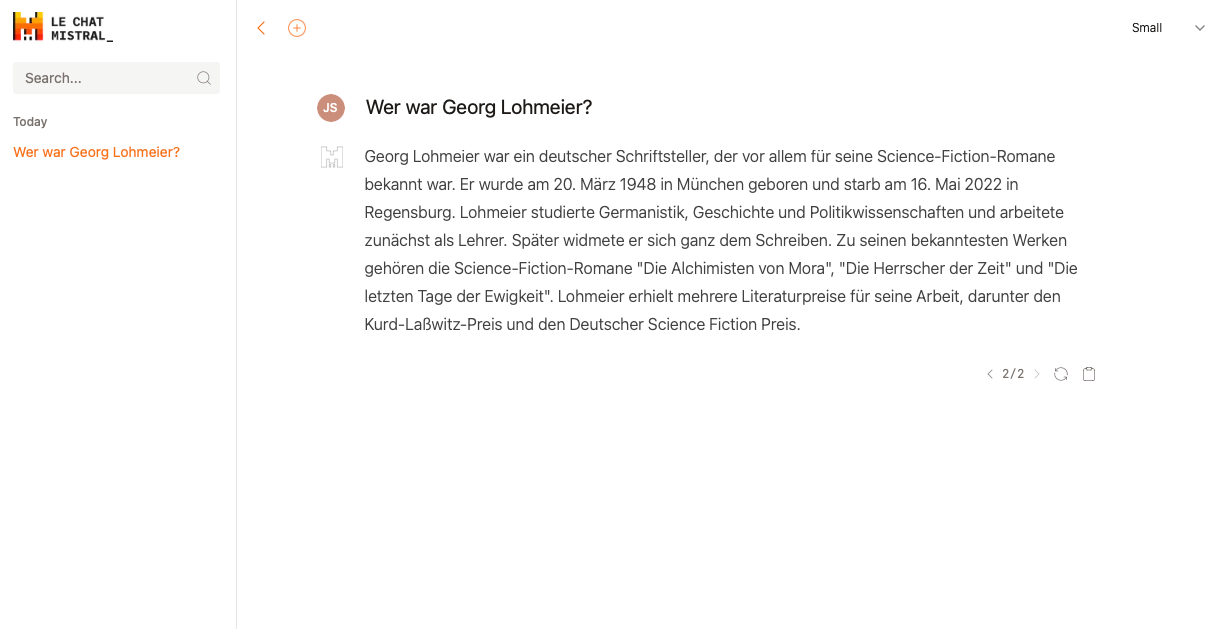
Das „small“-Modell beginnt nach dem sechsten Wort („Schriftsteller“) zu lügen und hört bis zum Schluss nicht mehr auf. Mehr muss man dazu nicht sagen.
Bei ChatGPT war ja das größere Modell etwas besser, bei Mistral ist das nicht anders:
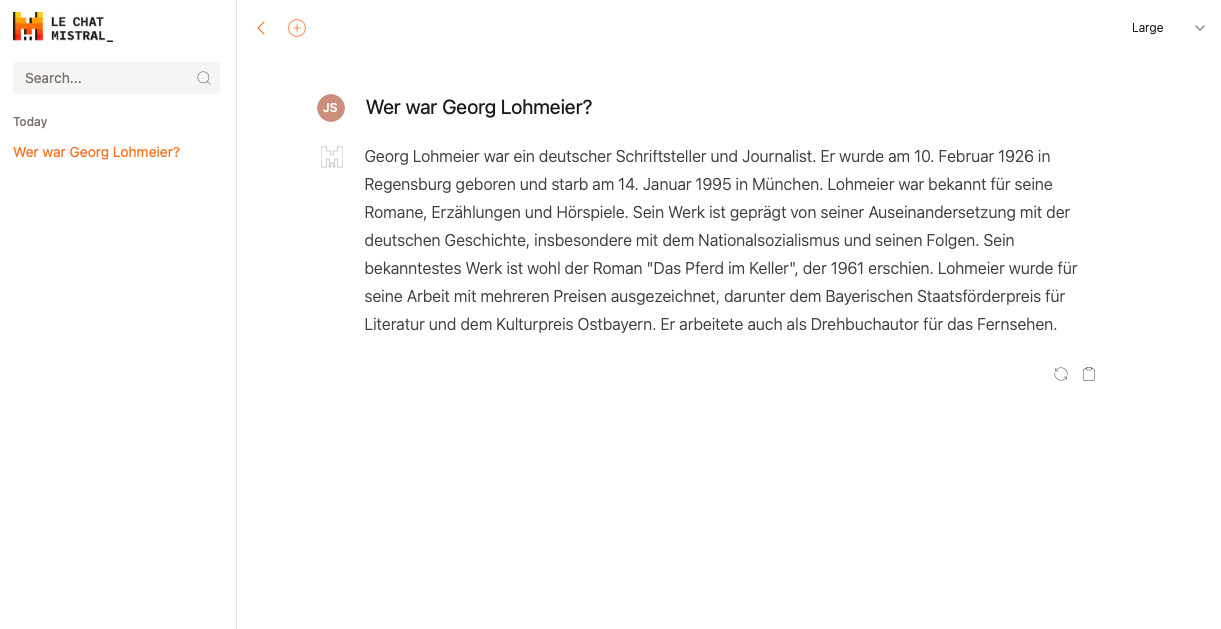
Das „large“-Modell ist lügt sich zwar auch ab Wort acht in immer neue Sphären, aber im letzten Satz rutscht ihm doch noch ein wahrer Fakt heraus. Das Geburtsdatum enthält zumindest das richtige Jahr. Gut, Mistral ist noch ein bisschen ein Underdog, fokussiert auf einen „offenen Ansatz“ – zumindest im Moment noch. Vielleicht ist hier ja die Modellqualität noch nicht ganz auf der Höhe.
Wie sieht es also bei Anthropic aus, deren Fokus auf Safety und Alignment liegt? „Making AI systems you can rely on“ ist ihr Motto.
Das "Sonnet"-Modell wird diesem markigen Spruch schon mal nicht gerecht. Es generiert einen einzigen korrekten Fakt – Geburtsjahr. Alles andere ist pure Phantasie, die nicht einmal mehr der richtige Kategorie („Schriftsteller“) entspricht.
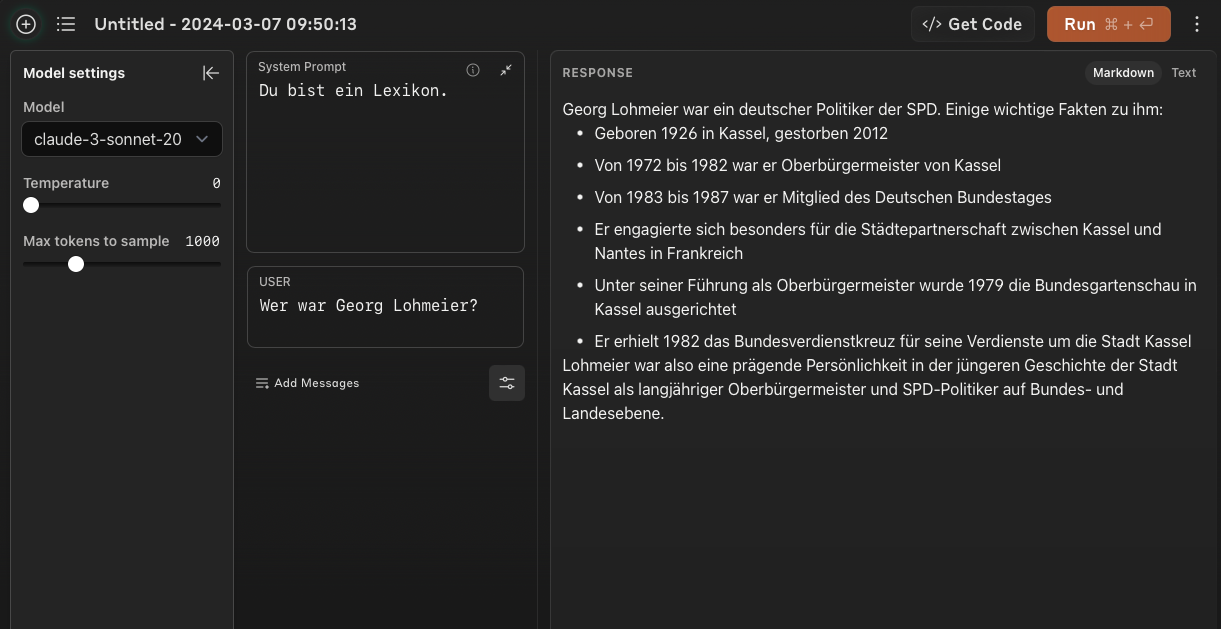
Auch hier geben wir der Fairness halber dem besseren Modell noch eine Chance:
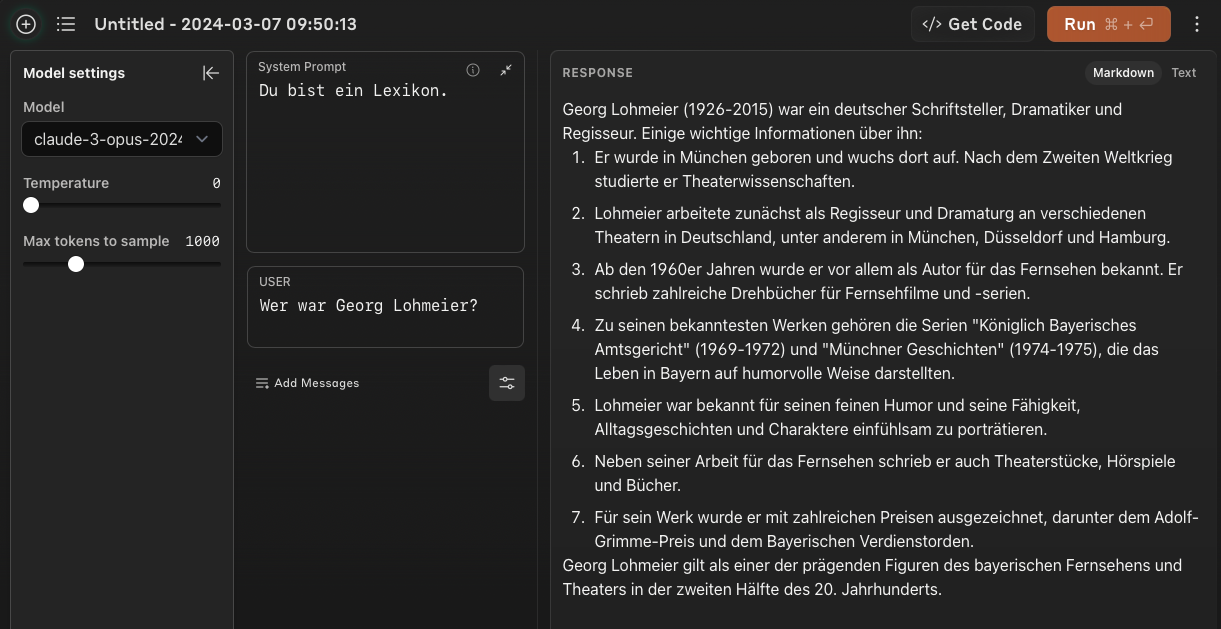
Wie zu erwarten war, ist jetzt ein größerer Teil der Fakten korrekt - wenn auch beileibe nicht alle.
Interessant ist bei Anthropics Claude der Einfluss, den marginale – und eigentlich sinnlose – Änderungen am System Prompt auf das Ergebnis haben:
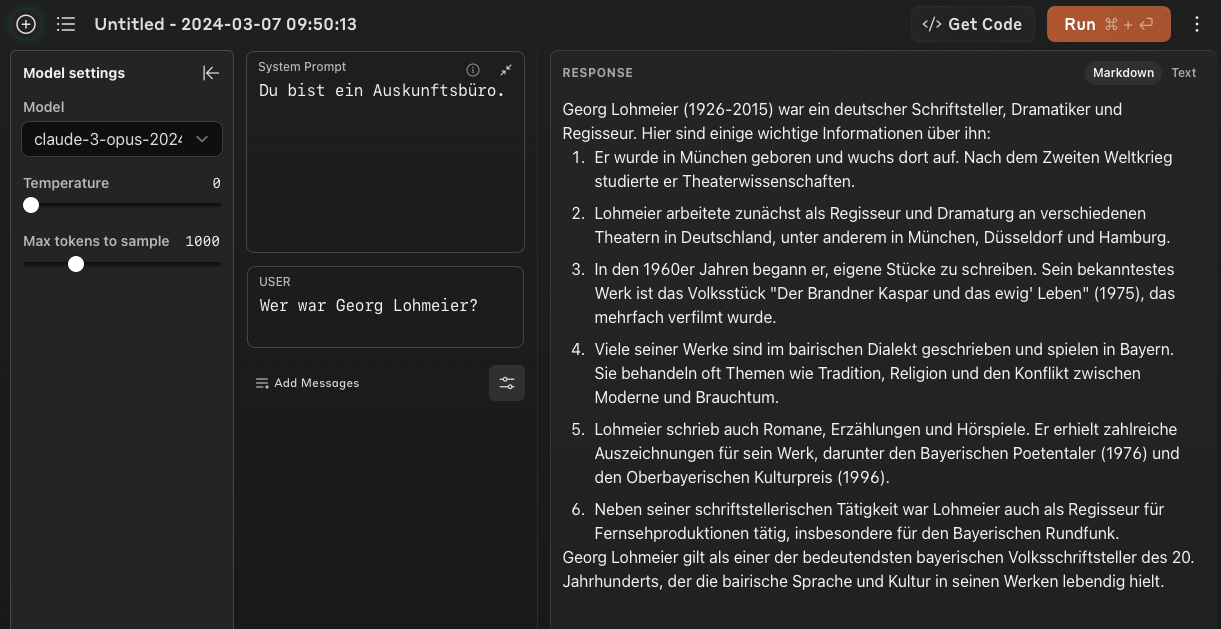
Der Wechsel von „Du bist ein Lexikon“ zu „Du bist ein Auskunftsbüro“ führt zu einem neuen, völlig inkorrekten Faktoid (Nummer 3) und spricht Herrn Lohmeier andere Auszeichnungen zu. Auch der „bairische Dialekt“ bzw. die „bairische Sprache“ spielt nur für das „Auskunftsbüro“ eine Rolle, nicht aber für das „Lexikon“.
Natürlich kann man argumentieren, „Prompt Engineering“ sei ja auch eine schwierige Wissenschaft und beide System Prompts seien eigentlich dämlich. Aber auch selbsternannte „Senior Prompt Engineers“ haben keine Informationen an der Hand, auf deren Basis sie solche Befindlichkeiten voraussehen oder deren Einfluss auf Halluzinationen beurteilen könnten. „Prompt Guessing, Probing & Hoping“ wäre also eigentlich die bessere Bezeichnung.
Was folgt daraus?
Sprachmodelle tun sich notorisch schwer damit, Fakten verlässlich abzurufen. Leider antworten sie aber auch fast nie mit „Ich weiß nicht“. Die Last, zwischen Halluzination und Wahrheit zu unterscheiden, liegt also vollständig auf dem Anwender. Das bedeutet effektiv, dass dieser Anwender die Informationen aus dem Sprachmodell überprüfen muss – indem er den Fakt, den er sucht, gleichzeitig aus einer anderen, verlässlichen Quelle bezieht. Als Wissensspeicher sind LLMs also mehr als nutzlos.
Sprachmodelle sind großartig darin, Wissen aufzubereiten, zusammenzufassen, in verschiedener Weise darzustellen, für bestimmte Zielgruppen zu formulieren – vorausgesetzt, dieses Wissen wird ihnen von außen, z.B. im Prompt via RAG, zugeführt.
Das sind deshalb die Anwendungen, die wir täglich bauen. Für alles andere gibt es Suchmaschinen.


