ChatGPT und der Ölteppich

„Data is the new oil“, so sagte im Jahr 2006 der britische Mathematiker Clive Humby. Wahrscheinlich war er sich nicht bewusst, wie richtig er lag und wie weit man diese Analogie treiben kann.
- Daten sind wie Öl, ohne Verarbeitung sind sie nutzlos.
- Daten sind wie Öl, wesentliche Prozesse werden von ihnen angetrieben.
- Daten sind wie Öl, sie sind – in gewissem Sinne – schlecht für die Umwelt.
- Daten sind wie Öl, sie sind wertvoll, obwohl in relativ großen Mengen vorhanden.
Einer der wesentliche Unterschiede ist aber, dass Daten sich im Gegensatz zu Öl nicht verbrauchen. Man kann die gleichen Datensätze immer wieder in verschiedenen Kontexten verwenden.
Klassisches Machine Learning hat immer zuerst bedeutet, Daten zu sammeln und vor allem, Daten aufzubereiten. Automatische Übersetzung zum Beispiel steht und fällt mit dem Vorhandensein sogenannter „alinierter Texte“, also von Dokumenten, die in zwei verschiedenen Sprachen vorliegen und idealerweise Satz für Satz gegenübergestellt werden können. Auf dieser (Daten)Basis kann dann ein Machine Learning Modell trainiert werden, das auch für neue Sätze das (oft) korrekte Gegenüber ausspuckt. Im Wettrennen solcher Systeme war oft entscheidend, wer die saubereren und größeren Datenmengen hatte und nicht, wer den besseren Algorithmus bzw. die bessere Technologie besaß.
Die technischen Ansätze basieren sowieso oft auf frei verfügbarer Forschung, die Daten machen den Unterschied.
Mit Deep Learning ist dieser Datenhunger noch deutlich größer geworden. Während vorherige Verfahren mit 100 Positivbeispielen pro Kategorie schon ganz gut funktionierten (z.B. 100 Finanznews vs 100 Politiknews zum Trainieren eines Classifiers), brauchten Deep Learning Verfahren mindestens eine Größenordnung mehr. Dafür funktionierte hiermit dann plötzlich so etwas Verrücktes wie Bildsuche bzw. Bildkategorisierung.
Mit Large Language Models (und anderen Formen generativer AI) haben wir die nächste Stufe der Datengier gezündet. Hier wird eigentlich nur noch von Milliarden geredet. Im dem Fall sind diese Inputdaten zwar nur unkategorisierte „Tokens“ statt manuell vorsortierter Dokumente, aber die verwendeten Datenmengen sind dennoch gigantisch.
Ein wesentlicher Unterschied ist allerdings, dass im Falle von ChatGPT und anderen solchen Modellen jemand anderes für mich alle möglichen bunten Daten gesammelt und zu einem Brei vermischt hat - einem Ölteppich sozusagen.
Dadurch kann das Modell ohne weitere Datenzufuhr fast alle Fragen beantworten, aber kann umgekehrt für keine Frage wirklich verlässliche, präzise oder auch nur reproduzierbare Antworten garantieren. Der große Datenbrei spuckt auf fast alles eine Antwort aus, aber je dünner die Datenlage im Trainingsset war, desto fragwürdiger wird sie.
Was? Aber ChatGPT wurde doch auf dem gesamten Wissen der Welt trainiert, oder nicht?
Selbst wenn das so wäre (sowohl „gesamt“ als auch „Wissen“ als auch „Welt“ sind vermutlich keine angemessenen Begriffe), benötigt es nicht nur ein Dokument zu jedem Thema, sondern sehr sehr viele, um am Ende faktisch korrekte Antworten zu geben. Man sieht das sehr schön, wenn man sich ein bisschen an den „Rand“ des Weltwissens begibt: Waren zu einem Thema wenig Dokumente im Trainingsset und überrumpelt man das System vielleicht noch mit abwegigen Abfragesprachen wie z.B. Deutsch, dann ist die Halluzination nicht weit:
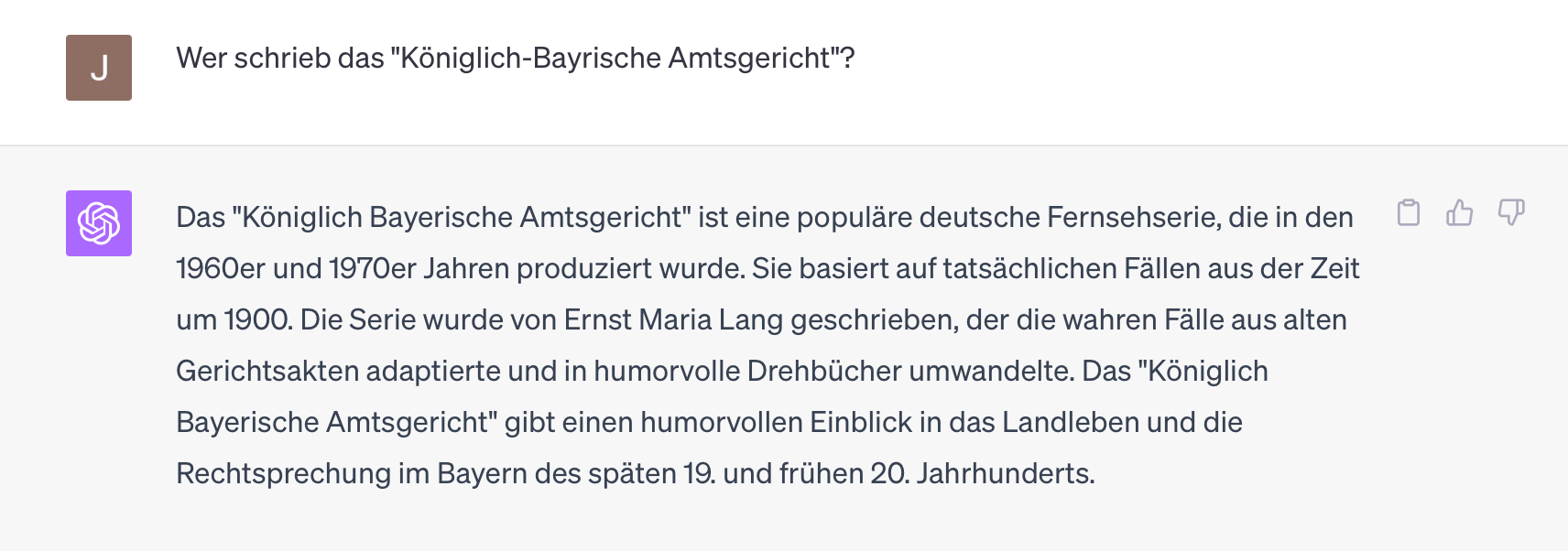
Nein, das ist nicht korrekt, Georg Lohmeier hat diese Serie geschrieben und die Fälle spielen alle 1911/12.
Aber vielleicht war ja der Bindestrich verwirrend, im Original schreibt es sich ohne diesen:
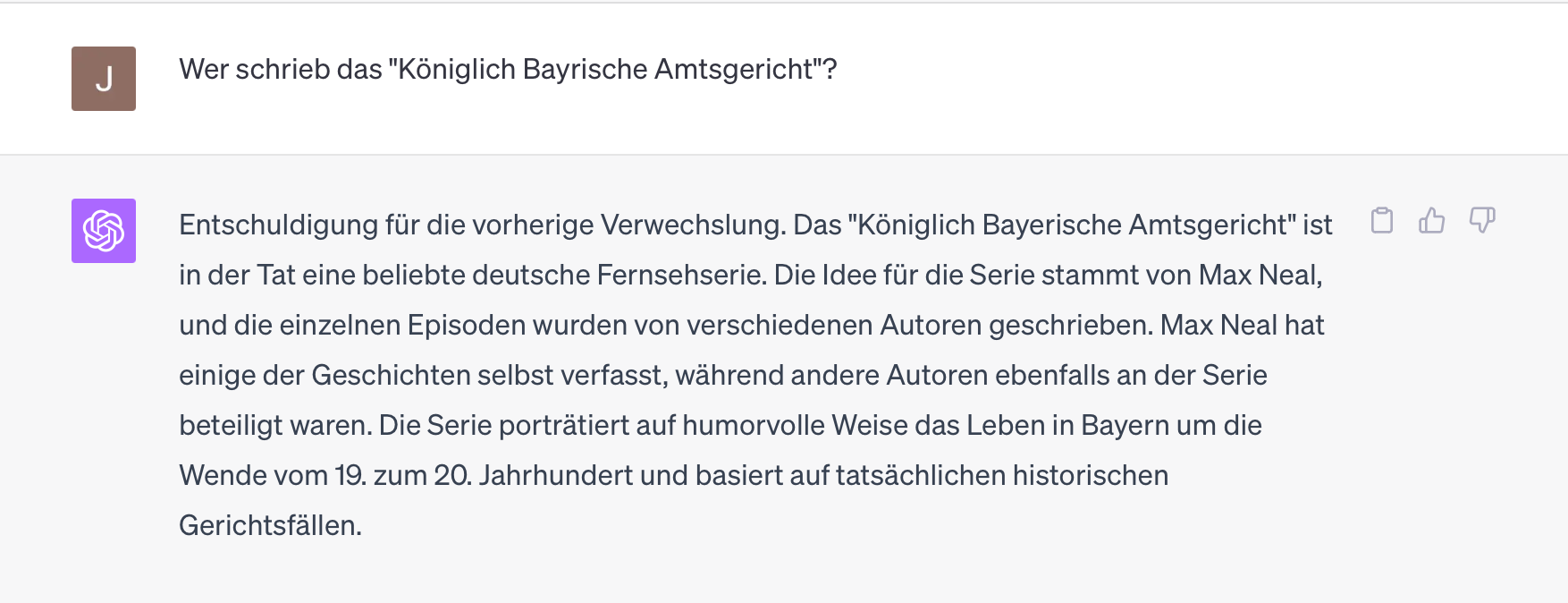
Ah ja, nein, das ist nicht weniger falsch. Interessanterweise bleibt das Modell in der richtigen „Umgebung“, sowohl Ernst Maria Lang als auch Max Neal sind im weitesten Sinne Humoristen aus Bayern. Aber kann der Bindestrich eine solche Umdeutung hervorrufen?
Probieren wir das lieber nochmal mit einer wörtlichen Wiederholung (im selben Chat-Fenster):
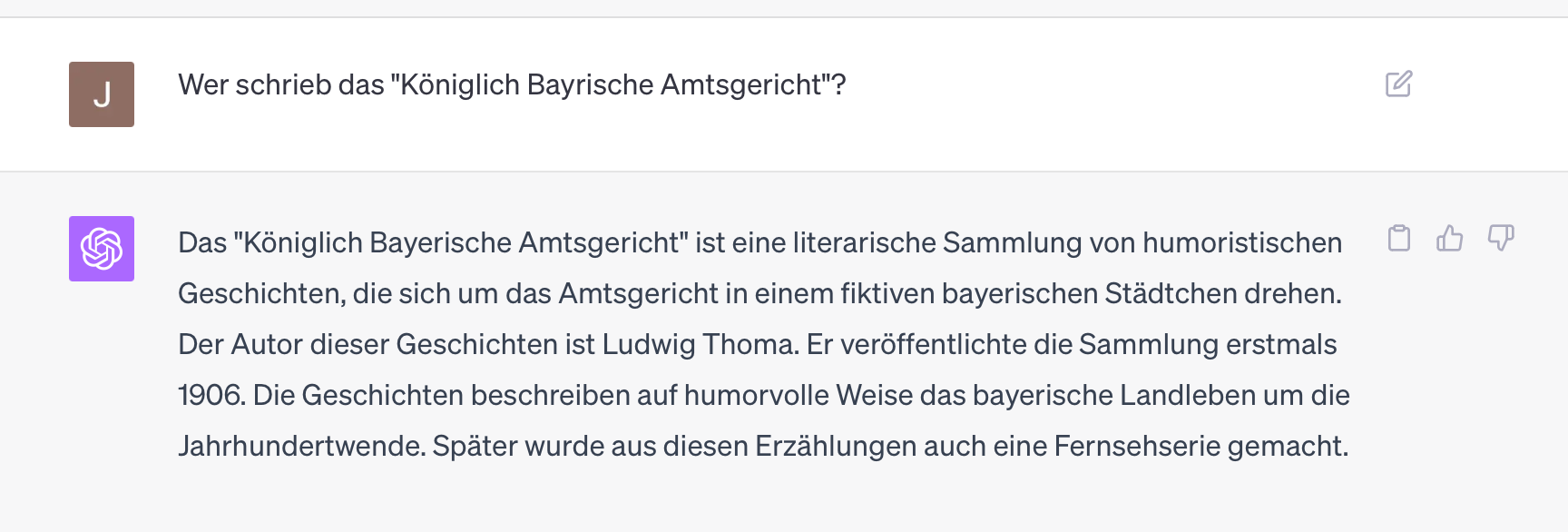
Ah, wieder ein bayrischer Humorist, wieder der Falsche. Für alle genannten Herren (inklusive dem echten Autor) existieren Wikipedia-Seiten und auch andere Informationen im Netz. Dennoch fantasiert ChatGPT-4 (in allerneuester Ausprägung vom 12. Sep 2023) sich lustig beliebigen Käse zusammen.
Rücken wir wieder etwas mehr in das Zentrum der Welt von ChatGPT, werden die Antworten wieder korrekt, konsistent und vor allem wiederholbar:
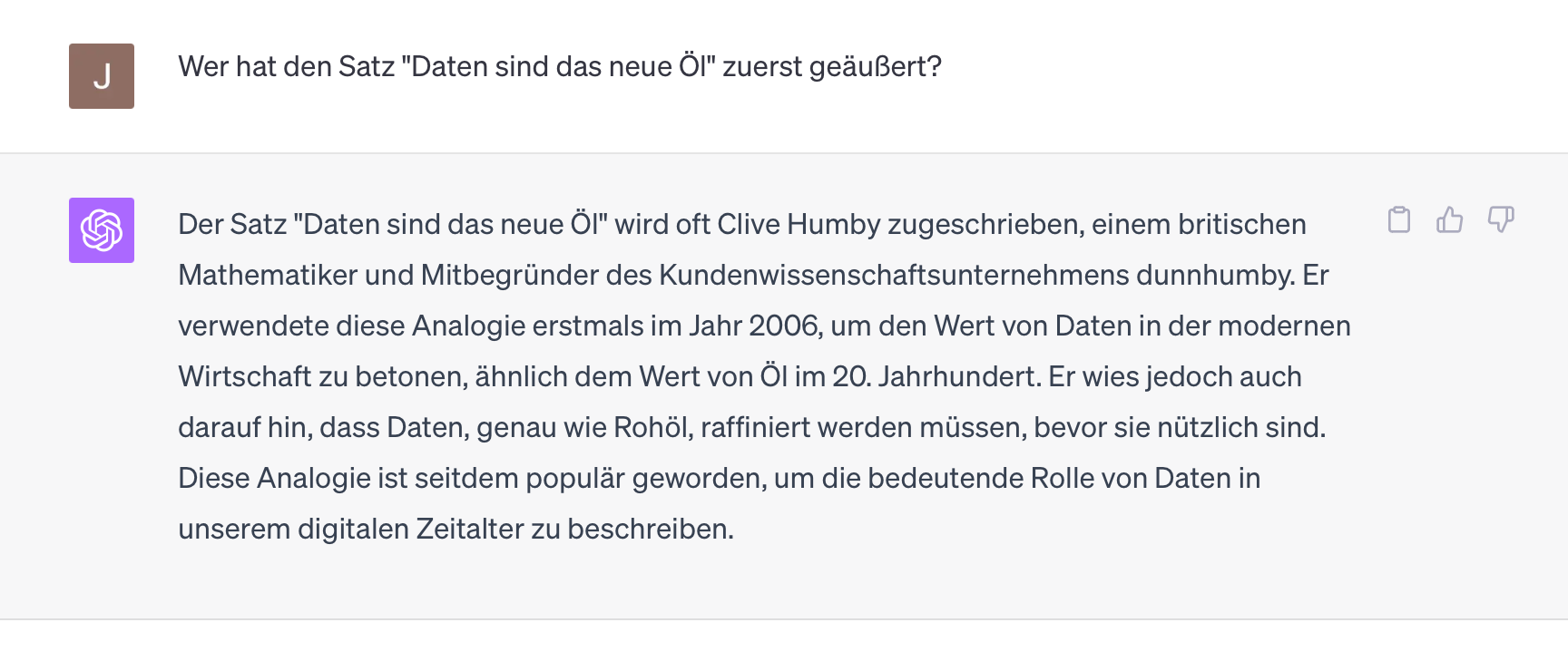
Jede Wiederholung dieser Frage erzeugt (für mich, Stand heute) die gleiche Antwort. Und selbst die englische Variante ist konsistent und quasi eine 1:1 Übersetzung der deutschen:

Aber ist das denn wichtig? Interessiert sich irgendjemand wirklich für das „Königlich Bayerische Amtsgericht“??
Vermutlich schon, aber das wesentlichere Problem ist, dass unzählige Start-Ups in extrem engen Nischen gegründet werden, mit dem Anspruch, für diese Nische ein tolles „AI-angetriebenes“ Produkt zu bauen, was in der Realität oft bedeutet, dass diese Produkte auf mehr oder minder phantasievolle Art Prompts an ChatGPT schicken und dessen Ausgaben weiterverarbeiten.
Das obige Beispiel dokumentiert aussagekräftig, welche Qualität von solchen Ansätzen zu erwarten ist, sobald man den üppigen Kern der OpenAi-Trainingsdaten verlässt.


